
ClickHouse: 1억 건의 데이터를 1초 만에 처리하는 실시간 OLAP 데이터베이스
들어가며
빅데이터 분석 환경에서 쿼리 응답 속도는 비즈니스 의사결정의 핵심입니다. 수십억 건의 로그 데이터를 실시간으로 분석해야 하는 상황에서 전통적인 RDBMS나 일반적인 NoSQL은 한계에 부딪히곤 합니다. 이때 해결사로 등장한 것이 바로 ClickHouse입니다. 1억 건의 데이터를 단 1초 만에 처리하는 압축 성능과 속도를 낼 수 있는 ClickHouse의 특징과 사용법을 정리했습니다1.
ClickHouse란?
ClickHouse는 온라인 분석 처리(OLAP)를 위해 개발된 컬럼 지향(Column-oriented) DBMS입니다. Yandex에서 오픈 소스로 공개한 이후, 현재는 실시간 분석 분야에서 가장 강력한 도구 중 하나로 자리 잡았습니다.
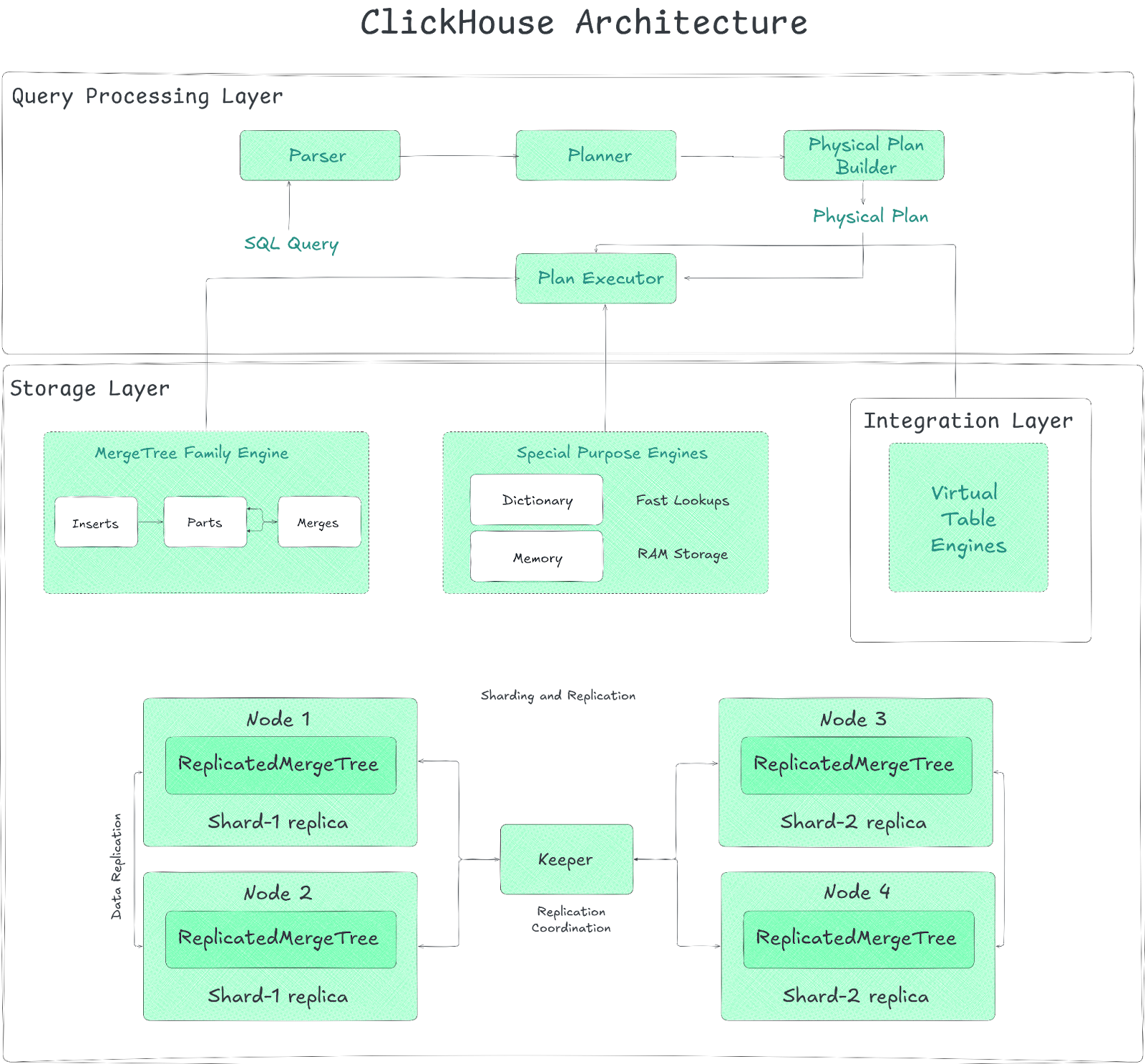
ClickHouse의 쿼리 처리 및 저장 계층을 포함한 전체 아키텍처 구조
주요 특징
- 컬럼 지향 저장 방식: 데이터를 열 단위로 저장하여 분석에 필요한 특정 열만 읽어올 수 있어 I/O 효율이 매우 높습니다.
- 데이터 압축: 유사한 데이터가 모여 있는 열 단위 특성상 압축 효율이 극대화됩니다2.
- 벡터화 쿼리 실행: CPU의 SIMD 명령어를 사용하여 데이터를 배열 단위로 처리하여 연산 속도를 높입니다.
- 강력한 SQL 지원: 표준 SQL을 지원하며, 윈도우 함수나 JOIN 연산도 가능합니다.
심화 아키텍처 분석
제공된 아키텍처 다이어그램을 바탕으로 ClickHouse의 내부 동작 원리를 조금 더 깊이 있게 살펴보겠습니다.
1. 저장 메커니즘: Parts & Merges
MergeTree 엔진에서 데이터가 삽입(Insert)되면 즉시 Parts라는 작은 데이터 조각이 생성됩니다. ClickHouse는 백그라운드에서 이 작은 조각들을 지속적으로 병합(Merges)하여 하나의 큰 데이터 덩어리로 만듭니다. 이 방식은 쓰기 부하를 줄이면서도 읽기 성능을 최적화하는 핵심 비결입니다.
2. 분산 환경과 확장성 (Sharding & Replication)
대규모 클러스터 환경에서는 ReplicatedMergeTree 엔진을 사용합니다.
- Sharding: 데이터를 여러 노드에 분산 저장하여 처리량을 늘립니다.
- Replication: 동일한 데이터를 여러 노드에 복제하여 고가용성을 보장합니다.
- Keeper: 다이어그램 중앙의 Keeper는 복제 노드 간의 상태를 동기화하고 조율하는 역할을 수행합니다 (ZooKeeper의 경량화 대체제).
3. 특수 목적 엔진과 통합 계층
- Special Purpose Engines: 메모리에 상주하는
Memory엔진이나 빠른 조회를 위한Dictionary엔진을 제공합니다. - Integration Layer: 외부 데이터베이스(MySQL, PostgreSQL 등)나 파일 시스템에 직접 연결할 수 있는 가상 테이블 엔진을 통해 데이터 통합이 용이합니다.
MergeTree 엔진 활용
ClickHouse의 가장 핵심적인 엔진은 MergeTree입니다. 데이터를 파티셔닝하고 백그라운드에서 병합하며 정렬 상태를 유지합니다.
테이블 생성 예시
-- 실시간 로그 저장을 위한 MergeTree 테이블 생성
CREATE TABLE logs (
event_date Date,
event_time DateTime,
user_id UInt32,
event_type String,
message String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(event_date)
ORDER BY (event_date, event_type, user_id)
SETTINGS index_granularity = 8192;
Materialized View: 실시간 집계의 핵심
ClickHouse의 Materialized View(MV)는 일반적인 RDBMS의 MV와는 완전히 다르게 동작합니다. 단순히 쿼리 결과를 저장하는 스냅샷이 아니라, 원본 테이블에 데이터가 삽입될 때마다 실시간으로 동작하는 인서트 트리거(Insert Trigger)에 가깝습니다.
MV의 동작 원리
- 원본 테이블에 데이터가
INSERT됩니다. - MV 정의에 포함된
SELECT쿼리가 해당 데이터 조각(Block)에 대해 즉시 실행됩니다. - 계산된 결과가 MV의 전용 저장 테이블(보통
SummingMergeTree나AggregatingMergeTree엔진 사용)에 적재됩니다.
실전 예제: 시간대별 이벤트 집계
-- 1. 집계 결과를 저장할 타겟 테이블 생성
CREATE TABLE hourly_event_stats (
event_hour DateTime,
event_type String,
total_count AggregateFunction(count, UInt64)
) ENGINE = AggregatingMergeTree()
ORDER BY (event_hour, event_type);
-- 2. Materialized View 생성 (원본 logs 테이블로부터 실시간 집계)
CREATE MATERIALIZED VIEW mv_hourly_stats
TO hourly_event_stats
AS SELECT
toStartOfHour(event_time) AS event_hour,
event_type,
countState() AS total_count
FROM logs
GROUP BY event_hour, event_type;
이렇게 구성하면 조회 시점에 수십억 건을 집계할 필요 없이, 이미 계산된 결과만 읽으면 되므로 극적인 성능 향상을 얻을 수 있습니다3.
실전 활용 시나리오
시나리오: 실시간 사용자 행동 분석
사용자가 웹사이트에서 클릭하는 모든 이벤트를 수집하여 실시간 대시보드를 구축하는 경우입니다.
- 데이터 수집: Kafka를 통해 유입되는 로그를 ClickHouse의
Kafka Engine으로 직접 구독합니다. - 데이터 변환: 앞서 설명한
Materialized View를 사용하여 원본 로그를 실시간으로 집계하여AggregatingMergeTree테이블에 저장합니다. - 조회: 집계된 테이블을 조회하여 1초 미만의 응답 속도로 대시보드 데이터를 제공합니다.
마무리
- OLAP 최적화: 대규모 데이터의 집계 및 분석 쿼리에 특화된 성능 제공
- 압축 및 속도: 컬럼 지향 저장과 벡터 연산으로 압축률과 처리 속도 극대화
- 실시간 집계: Materialized View를 통한 쓰기 시점(Write-time) 사전 집계로 조회 성능 최적화
- 확장성: Sharding과 Replication, Keeper를 통한 무한한 확장성과 고가용성 제공
- 유연한 통합: 다양한 특수 엔진과 통합 계층을 통해 외부 데이터 소스와 유연하게 연결
참고 자료:
-
ClickHouse 공식 문서 - ClickHouse 소개 및 시작 가이드 ↩
-
Column-oriented Storage - ClickHouse의 아키텍처와 컬럼 저장 방식 설명 ↩
-
ClickHouse Materialized Views 가이드 - MV의 내부 동작 및 활용 전략 ↩
댓글남기기